


What is DataOps? How it Work?


The term “DataOps” has become increasingly prevalent, especially in the data analytics industry, due to the need to comply with new regulations such as GDPR and CCPA. DataOps, or Data Operations, is an emerging discipline that combines agile development, continuous integration/continuous delivery (CI/CD), and lean manufacturing principles to streamline data management and analytics.
In fact, 74% of respondents in a recent IDC survey indicated that new compliance and regulatory requirements have accelerated the adoption of DataOps.
At its core, DataOps is a practice that helps organizations manage and govern data more effectively.
However, DataOps encompasses much more, including its own definition, principles, benefits, and real-life applications in modern companies. We will explore all of these aspects in this article!
What is DataOps?
DataOps is a set of practices, processes, and technologies designed to enhance data management and analytics. By combining a process-focused perspective on data with the automation techniques of Agile software development, DataOps aims to improve the speed and quality of data analytics while fostering a culture of rapid, continuous improvement and collaboration.
The term “DataOps” was first highlighted by Lenny Liebmann in 2014 and has since gained traction through the contributions of various thought leaders. Interest in DataOps has significantly grown over the past five years, as evidenced by increasing online searches and industry engagement.
Core Methodologies of DataOps
DataOps integrates principles from several methodologies:
- Lean Manufacturing: Focuses on efficiency, waste reduction, and continuous improvement.
- Agile Development: Emphasizes iterative development, flexibility, and collaboration.
- DevOps: Combines development and operations to enhance the speed and reliability of software delivery.
Here are the key elements:
-
Break down silos and foster cross-functional teamwork.
-
Collaborate, automate, and be agile throughout the data lifecycle.
-
Continually improve the process through feedback loops and monitoring.
By adopting data operations practices, your organization can achieve faster time to value, consistent data quality, and better data-driven decision-making.
How DataOps Works?
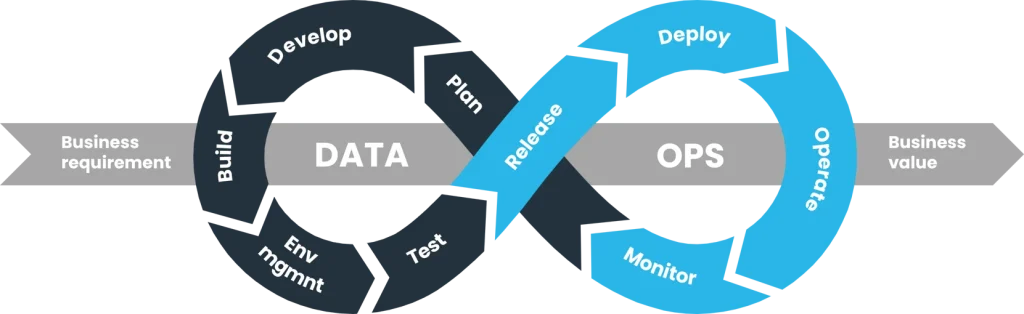
DataOps integrates agile processes for data governance and analytics development with DevOps practices for code optimization, product builds, and delivery. Beyond developing new code, optimizing and enhancing the data warehouse is essential. DataOps utilizes statistical process control (SPC) to monitor the data analytics pipeline, ensuring metrics remain within acceptable ranges, thereby improving data processing efficiency and quality. SPC alerts data analysts to anomalies or errors for quick resolution.
Steps to Implement an Agile DataOps Process:
- Plan: Collaborate with product, engineering, and business teams to establish KPIs, SLAs, and SLIs for data quality and availability.
- Develop: Create data products and machine learning models for your data application.
- Build: Integrate the code and/or data product into your existing tech or data stack.
- Manage Environments: Maximize data value through strategies like segregating environments, collaborating across branches, and setting environment variables.
- Test: Ensure your data conforms to business logic and meets operational standards.
- Release: Launch your data in a test environment.
- Deploy: Move your data into production.
- Operate: Use your data in applications such as dashboards and data loaders for machine learning models.
- Monitor: Continuously observe and report any irregularities in your data.
How Does DataOps Provide Value?
DataOps aims to address and eliminate inefficiencies within data pipelines. Here are three key ways it provides value:
- Encourage Team Collaboration: DataOps fosters better collaboration between data professionals and other IT roles by breaking down organizational silos. This leads to a more streamlined and efficient process overall. When everyone is aligned, issues can be identified and resolved more quickly. Teams are better equipped to research AI technologies, new analytics tools, and methods, and share their findings in a DataOps environment.
- Make Processes More Efficient: DataOps enhances efficiency by automating as much of the data pipeline as possible, including tasks like data quality checks, deployments, and monitoring. Automation frees up time for data professionals to focus on more critical tasks, such as analysis. Additionally, automated processes tend to be more accurate and reliable than manual ones, leading to fewer errors and more trustworthy data.
- Integrate Diverse Technologies: DataOps integrates diverse technologies to provide a comprehensive solution. This includes data storage and warehousing solutions, artificial intelligence, and analytics reporting tools. By integrating these technologies, organizations can get a complete view of their data pipeline and identify issues more easily. As the data industry continues to expand with new technologies, having a DataOps mindset and infrastructure helps data teams build a sustainable way of adopting these technologies as the company grows.
What Are The Principles of DataOps?

As a methodology, DataOps can vary depending on its industry and application. However, the DataOps Manifesto outlines 18 core principles that guide its implementation.
Here are the 18 DataOps Principles (summarized):
- Continually Satisfy Your Customer: DataOps prioritizes customers by ensuring quick and continuous delivery of data insights.
- Value Working Analytics: The performance of data analytics is measured by delivering insightful, accurate data within robust frameworks.
- Embrace Change: DataOps supports adapting to evolving customer needs by fostering real-time learning about changing behaviors. This requires data engineers to embrace new technologies, such as AI tools.
- It’s a Team Sport: DataOps requires a diverse set of skills, tools, and roles within analytics and data science to foster innovation and productivity.
- Daily Interactions: Stakeholders must collaborate daily to ensure project success.
- Self-Organize: The best analytics products come from teams that can self-organize.
- Reduce Heroism: DataOps teams should avoid reliance on individual heroics, focusing instead on sustainability and scalability.
- Reflect: Regular reflection on performance, customer feedback, and operational statistics supports continuous improvement.
- Analytics is Code: All analytics tools generate code that configures and processes data. This code should be treated like any other application source code.
- Orchestrate: Data, tools, environments, and teams must be well-orchestrated from start to finish for analytic success.
- Make it Reproducible: Everything must be versioned to ensure that code and configurations are reproducible.
- Disposable Environments: Technical environments and IDEs should be disposable to minimize experimental costs.
- Simplicity: In DataOps, simplicity is crucial, focusing on maximizing efficiency by reducing unnecessary work.
- Analytics is Manufacturing: DataOps treats analytic pipelines like lean manufacturing lines, emphasizing process efficiency.
- Quality is Paramount: Analytic pipelines should incorporate automated abnormality detection (jidoka) and continuous feedback mechanisms (poka-yoke) to maintain quality.
- Monitor Quality and Performance: Continuous monitoring of quality and performance helps catch variations early and provides statistics for operational insights. Collaboration between data and IT teams is essential to resolve quality issues.
- Reuse: Avoid repeating previous work to maintain efficiency.
- Improve Cycle Times: Always strive to minimize the time taken to address customer needs, develop analytic ideas, release products reproducibly, and refactor and reuse solutions.
DataOps Tools and Technologies
A variety of tools and technologies support the implementation of DataOps practices. These tools facilitate automation, collaboration, monitoring, and more. Key categories of DataOps tools include:
- Data Integration and ETL Tools: Tools like Apache Nifi, Talend, and Informatica automate data ingestion, transformation, and loading (ETL) processes, ensuring seamless data integration from multiple sources.
- Data Orchestration and Workflow Management: Tools like Apache Airflow, Prefect, and Luigi enable the orchestration of complex data workflows, managing dependencies, scheduling, and monitoring.
- Data Quality and Validation: Tools like Great Expectations, Deequ, and dbt (data build tool) provide automated data quality checks, validation rules, and data testing frameworks.
- CI/CD for Data Pipelines: Tools like Jenkins, GitLab CI, and CircleCI extend CI/CD capabilities to data pipelines, enabling continuous integration, testing, and deployment.
- Monitoring and Observability: Tools like Prometheus, Grafana, and ELK Stack (Elasticsearch, Logstash, Kibana) offer monitoring and observability for data pipelines, providing insights into performance and issues.
- Data Governance and Security: Tools like Apache Ranger, Collibra, and Alation ensure data governance, access control, and compliance with security policies and regulations.
- Collaboration and Documentation: Tools like Jupyter Notebooks, Confluence, and Slack facilitate collaboration, documentation, and communication among data teams.
Best Practices for Implementing DataOps
Implementing DataOps successfully requires adhering to best practices that align with its principles. Here are some key best practices:
- Adopt an Agile Approach: Implement agile methodologies like Scrum or Kanban to manage data projects. This enables iterative development, rapid feedback, and continuous improvement.
- Automate Everything: Strive to automate as many data processes as possible, from data ingestion to validation and deployment. Automation reduces manual effort and minimizes errors.
- Ensure Data Quality: Implement automated data quality checks and validation at every stage of the data pipeline. Use tools and frameworks to enforce data quality standards.
- Foster Collaboration: Encourage collaboration and communication among data engineers, data scientists, and business stakeholders. Regular meetings, shared documentation, and collaboration tools help align goals and address issues.
- Implement CI/CD for Data Pipelines: Apply CI/CD principles to data pipelines, ensuring continuous integration, testing, and delivery. Use version control for data code and configurations.
- Monitor and Observe: Continuously monitor data pipelines and processes to track performance, identify issues, and ensure data quality. Implement observability tools to gain insights into data workflows.
- Focus on Security and Governance: Implement robust security measures and governance policies to protect data and comply with regulations. Ensure access controls, encryption, and audit trails are in place.
- Scale with Demand: Design data pipelines and infrastructure to scale with growing data volumes and complexity. Use scalable architectures and technologies to maintain performance.
How to Get Started on Your DataOps Journey
Data has become a crucial resource for organizations to develop innovative products and services, personalize marketing efforts, and scale their businesses efficiently, without the large capital investments required in the past.
However, teams can only harness the power of data effectively if they have the right processes in place. DataOps provides these essential processes.
Bestarion can help you embark on your DataOps journey quickly by offering data management, end-to-end orchestration, CI/CD, automated testing and observability, and code management—all within an intuitive developer interface.
For faster development, parallel collaboration, developer efficiencies, data assurance, simplified orchestration, and data product lifecycle management, Bestarion is the destination for your data needs.