How Do AI Systems Identify Duplicate Data?

Duplicate data can be a significant challenge in data management, leading to inconsistencies, inefficiencies, and increased storage costs. AI systems have become increasingly sophisticated in identifying and managing duplicate data, offering more effective solutions than traditional methods. This article explores how AI systems identify duplicate data, the technologies and algorithms involved, and the benefits they bring to various industries.
What is Duplicate Data?
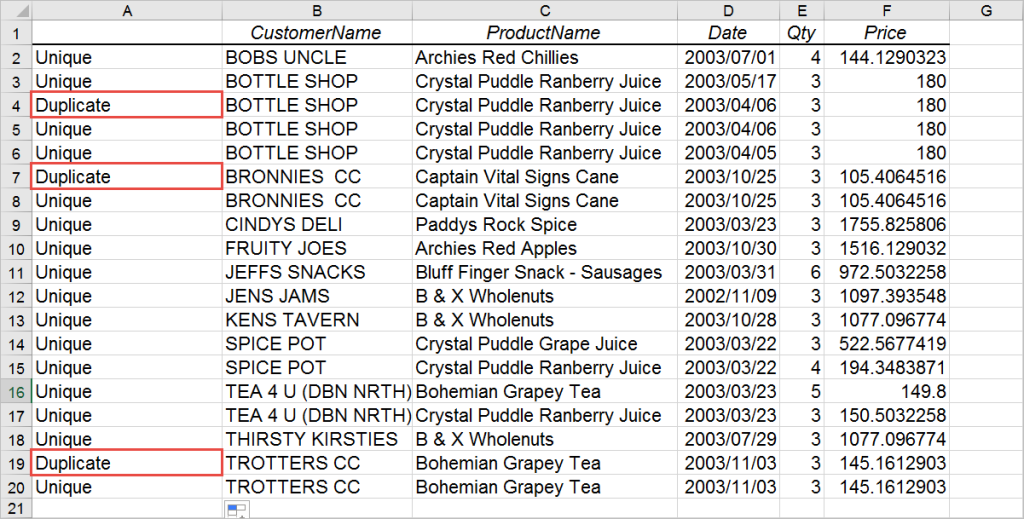
Duplicate data refers to identical or highly similar records within a dataset. It can occur due to various reasons such as human error, system glitches, or the integration of data from multiple sources. Duplication can manifest in different forms, including:
- Exact Duplicates: These are identical records that contain the same information in every field.
- Near Duplicates: These records are almost identical but may have slight variations due to typographical errors, different formats, or data entry inconsistencies.
Identifying and eliminating duplicate data is crucial for maintaining data quality, improving analytics accuracy, and ensuring efficient data management.
Traditional Methods of Duplicate Data Identification
Before diving into AI-based methods, it’s important to understand the traditional techniques for identifying duplicate data:
- Exact Matching: This involves comparing records to find identical entries. While effective for exact duplicates, this method falls short when dealing with near duplicates.
- Rule-Based Matching: This approach uses predefined rules and patterns to identify duplicates. For example, it might flag two records with the same name and date of birth as duplicates, even if their addresses differ slightly.
- Manual Review: Human analysts manually review datasets to identify duplicates. While this can be effective, it is labor-intensive, time-consuming, and prone to human error.
- Statistical Methods: Techniques like clustering and probabilistic record linkage are used to identify duplicates based on statistical similarities between records.
While these methods have been useful, they often struggle with large datasets and complex data structures. This is where AI systems come into play.
How AI Systems Identify Duplicate Data
AI systems leverage advanced algorithms and machine learning techniques to identify duplicate data more efficiently and accurately than traditional methods. Here are the key components of AI-based duplicate data identification:
1. Data Preprocessing
Before AI algorithms can identify duplicates, the data must be preprocessed to ensure it is clean and standardized. This process includes:
- Data Cleaning: Removing or correcting inaccuracies, inconsistencies, and missing values.
- Data Standardization: Converting data into a consistent format, such as standardizing date formats, addresses, or names.
Preprocessing is crucial as it ensures that the AI system works with high-quality data, increasing the accuracy of duplicate identification.
2. Similarity Metrics
AI systems use similarity metrics to compare records and determine how similar they are. Common similarity metrics include:
- Jaccard Similarity: Measures the similarity between two sets by comparing the intersection and union of the sets.
- Cosine Similarity: Measures the cosine of the angle between two vectors in a multi-dimensional space, commonly used for text data.
- Levenshtein Distance: Calculates the minimum number of single-character edits required to transform one string into another.
These metrics help AI systems quantify the similarity between records, allowing them to identify both exact and near duplicates.
3. Machine Learning Models
Machine learning models are at the core of AI-based duplicate data identification. These models can be trained to recognize patterns and similarities in data, even when they are not explicitly defined. Common machine learning models used include:
- Supervised Learning Models: These models are trained on labeled datasets, where duplicates are marked as such. The model learns to identify duplicates based on features like similarity scores and patterns.
- Unsupervised Learning Models: These models do not require labeled data and can identify duplicates by clustering similar records together based on learned patterns.
- Semi-Supervised Learning Models: These models combine the strengths of both supervised and unsupervised learning, using a small amount of labeled data to improve the accuracy of the model on larger, unlabeled datasets.
4. Natural Language Processing (NLP)
NLP techniques are essential for identifying duplicates in unstructured or semi-structured data, such as text records. NLP algorithms can understand and interpret the meaning of text, enabling AI systems to:
- Identify Synonyms and Variants: Recognize different terms or phrases that refer to the same entity, such as “NYC” and “New York City.”
- Handle Typographical Errors: Detect and correct typos or misspellings that might otherwise prevent exact matching.
- Contextual Analysis: Understand the context in which words or phrases are used, helping to differentiate between records that may seem similar but refer to different entities.
5. Entity Resolution
Entity resolution is the process of identifying and merging records that refer to the same real-world entity, such as a person, product, or organization. AI systems use entity resolution techniques to:
- Detect Cross-Domain Duplicates: Identify duplicates across different data sources or domains, even when the records are in different formats or structures.
- Merge Duplicates: Automatically merge duplicate records into a single, accurate record, preserving the most relevant information.
Entity resolution is particularly useful in scenarios where data from multiple sources needs to be integrated, such as in customer relationship management (CRM) systems or supply chain management.
6. Deep Learning
Deep learning, a subset of machine learning, involves using neural networks with multiple layers to identify complex patterns in data. In the context of duplicate data identification, deep learning models can:
- Handle Complex Data Types: Identify duplicates in complex data types, such as images, audio, or video.
- Improve Accuracy: Achieve higher accuracy in identifying duplicates by learning intricate patterns that simpler models might miss.
Deep learning models are particularly effective in scenarios where traditional methods struggle, such as when dealing with large, unstructured datasets.
7. Feedback Loops and Continuous Learning
AI systems can be designed to continuously learn and improve over time. By incorporating feedback loops, these systems can:
- Refine Algorithms: Adjust algorithms based on new data or user feedback, improving accuracy and reducing false positives.
- Adapt to Changing Data: Stay up-to-date with evolving data, ensuring that duplicate identification remains effective even as data patterns change.
Continuous learning is essential in dynamic environments where data is constantly changing or growing.
Read more: Top 20 Most Popular Data Science Tools for 2024
Benefits of AI-Based Duplicate Data Identification

AI-based duplicate data identification offers numerous benefits to businesses and organizations:
- Increased Efficiency
AI systems can process large volumes of data quickly and accurately, significantly reducing the time and effort required to identify duplicates. This is especially valuable for organizations dealing with big data or large-scale databases.
- Improved Data Quality
By accurately identifying and eliminating duplicates, AI systems help maintain high data quality. This leads to more reliable analytics, better decision-making, and improved overall business performance.
- Cost Savings
Reducing duplicate data can lead to significant cost savings, both in terms of storage costs and the resources required to manage and maintain data. AI systems can automate the process, further reducing costs associated with manual data cleaning and validation.
- Enhanced Customer Experience
For businesses that rely on customer data, such as e-commerce platforms or CRM systems, eliminating duplicates ensures that customer profiles are accurate and up-to-date. This enables personalized marketing, improved customer service, and a better overall customer experience.
- Scalability
AI systems are highly scalable, making them suitable for organizations of all sizes. Whether you’re a small business or a large enterprise, AI-based duplicate data identification can be tailored to meet your needs.
- Compliance and Security
Accurate data management is essential for compliance with data protection regulations, such as GDPR. AI systems help organizations ensure that data is accurate, up-to-date, and secure, reducing the risk of non-compliance.
Read more: A Complete Guide to Robotic Process Automation (RPA)
Challenges and Considerations
While AI-based duplicate data identification offers many advantages, there are also challenges and considerations to keep in mind:
- Data Privacy
Handling large volumes of data, especially sensitive or personal data, raises concerns about privacy and security. Organizations must ensure that AI systems comply with data protection regulations and safeguard customer information.
- Model Accuracy
AI models are not infallible, and there is always a risk of false positives (incorrectly identifying non-duplicates as duplicates) or false negatives (failing to identify actual duplicates). Continuous monitoring and refinement of models are necessary to maintain accuracy.
- Resource Requirements
Implementing AI systems requires significant computational resources, especially for deep learning models. Organizations must ensure they have the necessary infrastructure in place to support AI-based duplicate data identification.
- Integration with Existing Systems
AI systems must be seamlessly integrated with existing data management and analytics tools to be effective. This may require additional development work and collaboration between different teams within an organization.
Partner with Bestarion for Enhanced Data Quality
As a software company, Bestarion prioritizes the efficiency and accuracy of data processing by integrating cutting-edge tools and technologies, with a particular emphasis on AI-based tools for handling duplicate data. Our solutions are designed to minimize manual processes, allowing for more streamlined operations and faster decision-making.

AI-Based Tools for Duplicate Data Processing
Duplicate data can significantly hinder business processes, leading to inaccurate reporting, inefficient resource usage, and unnecessary costs. Our AI-based tools address this issue by automatically identifying and managing duplicate entries with precision. These tools utilize advanced algorithms and machine learning models to detect both exact and near duplicates, ensuring that your data is clean, consistent, and reliable.
How Our AI-Based Tools Work
- Data Preprocessing: We begin by cleaning and standardizing the data to ensure it’s in the best possible shape for analysis. This step includes removing inaccuracies, standardizing formats, and filling in any missing information.
- Duplicate Detection: Our AI models then analyze the data using sophisticated similarity metrics such as Jaccard similarity, Levenshtein distance, and cosine similarity. These metrics allow the system to compare records at a granular level, identifying duplicates even when they are not exact matches.
- Entity Resolution: After detecting potential duplicates, our tools perform entity resolution to merge records that refer to the same real-world entity. This ensures that you have a single, accurate record for each entity, whether it’s a customer, product, or transaction.
- Continuous Learning: The AI models are continually updated with new data and feedback, improving their accuracy and adapting to changes in data patterns. This means that as your business grows and evolves, our tools will continue to deliver high-quality results.
Benefits of Our AI-Based Duplicate Data Processing
- Enhanced Data Accuracy: By eliminating duplicates, our tools ensure that your data is accurate and up-to-date, leading to more reliable insights and better decision-making.
- Cost Efficiency: Reducing duplicate data lowers storage costs and minimizes the need for manual data cleaning, saving both time and money.
- Scalability: Our solutions are designed to handle large datasets, making them suitable for businesses of all sizes.
- Compliance and Security: We adhere to the highest industry standards for data privacy, security, and compliance. Our tools ensure that your data is managed in a secure and compliant manner, reducing the risk of breaches and non-compliance.
By choosing our data processing services, you gain access to a partner that is dedicated to leveraging the latest technologies to improve your business operations. With our focus on automation, compliance, AI-driven insights, and industry-specific solutions, we help you unlock the full potential of your data while ensuring security and accuracy.
Let us handle your data processing needs so you can focus on what you do best—growing your business.